Most roundups of generative engine optimization tools read like vendor brochures. They list dashboards, repeat marketing claims about “AI visibility,” and never check whether any of it moves a real metric. So we did the opposite. We ran each major generative engine optimization tool through hands-on testing, then cross-checked the visibility numbers they reported against first-party Google Search Console data — because if a tool says you’re gaining citations but your search footprint says otherwise, you deserve to know which signal is lying.
This is built for SEO professionals, SaaS content teams, growth marketers, and agencies trying to track and improve brand presence in ChatGPT, Perplexity, Gemini, and Claude. The big distinction we keep returning to: most of these tools monitor visibility, very few produce the content that earns it, and most budgets get spent on the wrong half. We’ll show you which is which, name the free and open-source options nobody else lists, and give you a decision matrix that maps tools to your team size and budget.
What Is a Generative Engine Optimization Tool (and What It Isn’t)
A generative engine optimization tool helps you measure and improve how your brand shows up inside AI-generated answers — the responses ChatGPT, Perplexity, Gemini, and Claude produce instead of a list of blue links. In practice, “GEO tool” gets stretched to cover two very different things: software that watches what AI engines say about you, and software that helps you create the content those engines pull from. Conflating the two is the single most expensive mistake teams make this year.
A GEO tool is not a magic citation generator. None of them can force an LLM to mention you. What the good ones do is surface where you appear, where competitors beat you, and which prompts you’re missing — and the best of the bunch connect that intelligence to a content workflow that actually closes the gap.
How GEO differs from SEO and AEO
The acronyms overlap more than the marketing suggests. SEO is optimizing for ranked results in a search index. AEO (answer engine optimization) targets direct answers — featured snippets, voice answers, and AI Overviews that resolve a query in one box. GEO narrows further to the generative, LLM-native layer: getting your brand woven into and cited by conversational models that synthesize an answer from multiple sources.
Here’s the part vendors won’t tell you: the underlying work barely changes. Crawlable pages, clear topical relevance, demonstrated authority, and genuinely useful content serve all three at once. We’ve made this case before in detail — why GEO and AEO are outcomes of strong traditional SEO, not separate disciplines — and it holds up in testing. A page that ranks well and answers a question cleanly is the same page an LLM is most likely to retrieve and cite. GEO isn’t a parallel universe; it’s a downstream result of doing the foundational work properly.
If your focus is the broader answer-engine space rather than the LLM-native engines specifically, the companion piece on AEO tools and how they compare to GEO platforms covers that lens — monitoring-vs-production, a transparent rating rubric, and free alternatives — sized for answer engines as a category. This article stays tight on the generative engines: ChatGPT, Perplexity, Gemini, Claude, and DeepSeek.
Why LLM-native engines (ChatGPT, Perplexity, Gemini, Claude) change the game
Classic search rewards a ranked position. Generative engines reward being retrievable and quotable. When someone asks Perplexity for the best project management tool, the model retrieves a handful of sources, synthesizes them, and cites a few. You’re not competing for position three; you’re competing to be one of the four or five sources the model decided were worth pulling into its answer.
That shifts the optimization target. Exact-match keyword density matters less. Clear claims, structured comparisons, distinct data points, and self-contained passages matter more, because those are the chunks a model can lift cleanly. Each engine also behaves differently — Perplexity cites heavily and visibly, ChatGPT cites more selectively, Gemini leans on Google’s index, and Claude is conservative about sourcing. A GEO tool’s job is to make that invisible behavior visible.
Monitoring tools vs. production tools: where most budgets get wasted
This is the fault line that runs through every product in this article. Monitoring tools answer the question “Am I being cited?” They run prompts across engines, track share of voice, and chart your presence over time. Production tools answer “How do I earn more citations?” They turn insight into briefs, drafts, and published pages.
The budget waste is predictable: teams buy a monitoring dashboard, watch their share-of-voice number, and have no workflow to actually change it. A dashboard that tells you you’re invisible in Perplexity is useless if nothing in your stack helps you publish the content that would fix it. We dig into this exact split — and the GSC-first framework behind it — in our guide to monitoring tools vs. production tools in the AI visibility stack . The short version: monitoring is necessary, but it’s the cheap, commoditized half. Production is where citations are actually won.
How LLM-Powered Engines Retrieve, Rank, and Cite Your Content
To evaluate a GEO tool honestly, you have to understand what it’s measuring. AI engines don’t rank pages the way Google’s ten blue links do — they retrieve, synthesize, and selectively attribute. Get the mechanics wrong and you’ll buy a tool that optimizes for the wrong signal.
Retrieval-augmented generation (RAG) and the retrieval gate
Most cited AI answers are produced through retrieval-augmented generation: the model queries an index or the live web, pulls back candidate passages, reranks them, and writes an answer grounded in what it retrieved. The critical implication is the retrieval gate — if your content isn’t retrieved, it cannot be cited, no matter how good it is. Retrieval depends on the same fundamentals that drive search: discoverable, crawlable, semantically relevant pages with clear chunk-level meaning.
This is where a lot of GEO advice goes sideways, because the technical layer underneath it is genuinely involved — vector search, live web fetching, and reranking all decide what makes it past the gate. We’ve broken down how RAG and retrieval mechanics determine which pages get cited in SEO terms, so we won’t repeat the full technical walkthrough here. The takeaway for tool selection: a GEO tool that only tracks final citations, with no view into whether you’re even retrievable, is measuring the scoreboard and ignoring the field.
Query fan-out and how prompts get decomposed
Generative engines rarely run your query as a single search. They decompose it — “best generative engine optimization tools for a small agency” might fan out into separate retrievals for GEO tools, agency pricing, small-team workflows, and AI visibility tracking, then merge the results. This query fan-out is why a single page rarely wins an entire answer, and why broad topical coverage beats one keyword-stuffed page.
Different engines fan out and attribute differently, and that variance matters when you read a tool’s visibility report. We cover the specifics of query fan-out and citation selection across AI engines elsewhere, including how the same prompt produces different source sets in different models. For tool evaluation, the practical question is whether a platform tracks the decomposed sub-queries or just the headline prompt — the former gives you something to act on, the latter gives you a vanity chart.
How citation selection actually works across ChatGPT, Perplexity, Gemini, Claude, and DeepSeek
Once candidates are retrieved, the model picks what to cite based on relevance, source authority, recency, and how cleanly a passage answers the decomposed query. The behavior diverges by engine:
- Perplexity is citation-heavy and transparent, surfacing numbered sources for almost every claim — the easiest engine to measure and to win with strong structured content.
- ChatGPT (with browsing or search) cites more selectively and leans on authority signals; it often synthesizes without naming every source.
- Gemini is tightly coupled to Google’s index, so traditional ranking strength carries over heavily.
- Claude is conservative, citing fewer sources and favoring high-trust ones.
- DeepSeek behaves closer to a search-grounded model with its own retrieval quirks, and few monitoring tools cover it well yet.
No tool tracks all five with equal fidelity. When a vendor claims “full coverage across every AI engine,” treat it as a starting hypothesis to test, not a fact.
How We Tested These Generative Engine Optimization Tools
We wanted results you could replicate, not impressions. Every claim in the reviews below comes from hands-on use and a disclosed process.
Our hands-on testing methodology, fully disclosed
We set up a real brand profile and a fixed prompt set of 40 buyer-intent and informational queries spanning the SEO/GEO category, then ran the same set through each tool over a four-week window. We logged: which engines each tool actually queried, how often data refreshed, whether reported citations matched what we saw running the prompts manually, and what each platform let us do with the findings beyond viewing a chart. Where a tool offered content production features, we generated and reviewed real briefs and drafts. No vendor was given advance notice, and nothing here is sponsored.
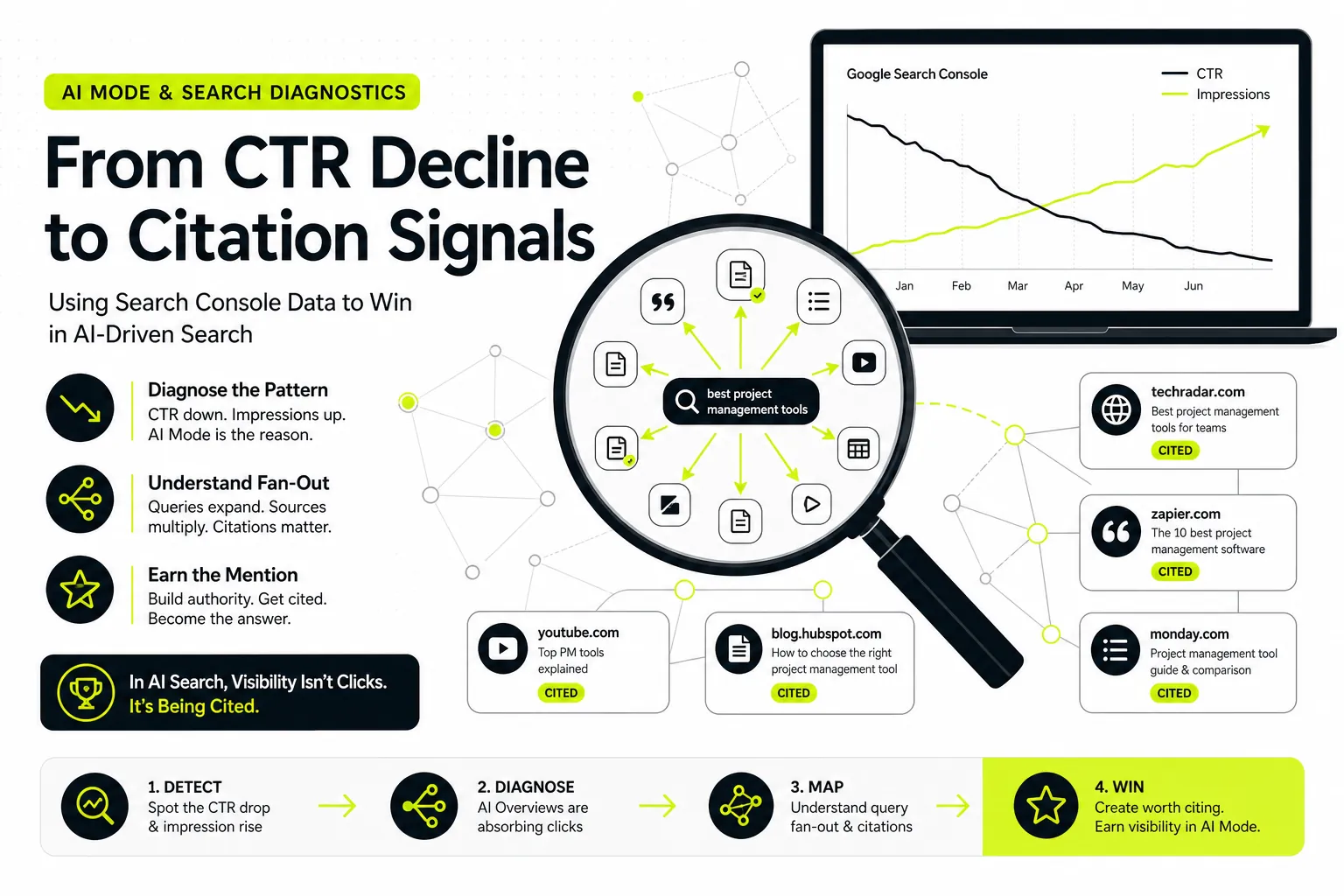
Cross-validating vendor visibility claims against first-party GSC data
This is the step that separates this roundup from the rest. For the same brand and topic set, we pulled Google Search Console data — impressions, clicks, and query coverage — and compared it against each tool’s visibility scores. The logic is simple: AI engines, especially Gemini and Perplexity, lean heavily on the open web and Google’s index, so a brand genuinely gaining ground in generative answers usually shows correlated movement in GSC query coverage and impressions. Where a tool reported rising “AI visibility” with zero corresponding signal in GSC, we flagged the metric as unverified. It’s not a perfect proxy, but it’s a first-party reality check that vendor dashboards can’t fudge.
Scoring criteria: accuracy, production capability, integration depth, and pricing
We scored each tool on four axes:
- Accuracy — did reported citations and share-of-voice hold up against manual checks and GSC?
- Production capability — can it create content, or only measure it?
- Integration depth — does it connect to GSC, your CMS, or your existing stack?
- Pricing — what you actually get per tier, not the headline number.
Production capability is weighted highest, because measurement without a path to action is the most common way teams overpay.
The Best Generative Engine Optimization Tools Reviewed
Here’s the hands-on verdict on the major generative engine optimization tools, grouped roughly from enterprise monitoring down to lightweight and emerging options. Read every one as monitoring-first unless noted otherwise — the production gap is the recurring theme.
Profound — enterprise AI visibility and citation monitoring
Profound is the most polished enterprise monitoring platform we tested. It tracks brand mentions and citations across the major engines, breaks down share of voice by prompt and competitor, and surfaces the sources models pull from. In testing, its citation tracking was among the most accurate, and its engine coverage was broad. The catch is the one that defines this whole category: Profound tells you, in great detail, where you stand — it does not write the content that changes where you stand. Pricing sits firmly in the enterprise band, so it’s a fit for large brands with a separate content team to act on the data.
AthenaHQ — AI search attribution and share-of-voice analytics
AthenaHQ leans into attribution: connecting AI visibility to share of voice and, increasingly, to downstream traffic and conversions. Its analytics were among the cleaner ones we reviewed, with solid competitive benchmarking. Accuracy held up reasonably against our manual prompt checks. As with Profound, it’s a measurement and analytics layer — strong for marketing teams that need to report on AI visibility to stakeholders, lighter on helping you produce what moves the number.
Semrush AI Visibility / AIO toolkit
Semrush bolted AI visibility tracking onto its enormous SEO suite, which is its biggest advantage and its biggest tell. If you already live in Semrush, the AIO toolkit lets you watch AI Overview and engine presence alongside your existing keyword and backlink data — and that integration with traditional ranking data is genuinely useful, since it reinforces that GEO rides on SEO. The AI-specific data was decent but less granular than dedicated monitors, and the production side is the same content tooling Semrush already offered, not a GEO-native workflow. Good value if you’re consolidating tools; not the deepest GEO monitor on its own.
Writesonic AI Search Visibility
Writesonic is one of the few vendors trying to fuse monitoring with content generation, which makes it more interesting than a pure dashboard. Its AI Search Visibility tracking covers the main engines, and it pairs that with its content-creation tools. In practice the production side is general-purpose AI writing rather than a GSC-grounded, search-data-driven workflow, so drafts needed heavy editing to be genuinely citable. Still, for a small team wanting monitoring and a writing assist under one login, it’s a reasonable middle ground.
Rankscale AI — focused AI search visibility tracking
Rankscale does one thing and does it cleanly: track AI search visibility without the bloat. Setup was fast, the prompt-level reporting was clear, and pricing is friendlier than the enterprise tier. Engine coverage was solid for the majors. It’s purely monitoring — no production layer — but if you want an accurate, no-nonsense visibility tracker without paying enterprise rates, it earned its place in testing.
Peec AI — competitive share-of-voice benchmarking
Peec AI is built around competitive benchmarking: how your share of voice in AI answers stacks against named rivals, prompt by prompt. We found its competitor views the most actionable of the benchmarking-focused tools, which makes it a strong pick for teams whose main question is “are we losing to a specific competitor in AI answers?” It’s monitoring through and through, but it’s good at the slice it owns.
Goodie AI and GetCito — emerging GEO platforms
Goodie AI and GetCito represent the newer wave of GEO-native platforms pushing past pure monitoring toward optimization guidance. Both track visibility and layer on recommendations for improving citation likelihood — content gaps, suggested topics, structural fixes. In testing the recommendations were promising but uneven, and the products are young enough that coverage and accuracy are still stabilizing. Worth watching, and worth a trial if you want optimization hints alongside monitoring, but verify their visibility data against your own checks before trusting the numbers.
Otterly AI — lightweight prompt-level answer monitoring
Otterly AI is the lightweight, prompt-level monitor — you define prompts, it tracks how AI engines answer them and whether you appear, with brand and link mention tracking. It’s affordable, quick to set up, and ideal for solo marketers or small teams who just want to know if they’re showing up for their core prompts. No production capability, modest engine depth, but honest about what it is and priced to match.
BrightEdge Generative Parser and enterprise GEO suites
BrightEdge brought generative parsing into its established enterprise SEO platform, tracking how AI engines and AI Overviews represent your content at scale. Like other enterprise suites, its strength is integrating AI visibility with a mature content and ranking dataset, and its weakness is cost plus the assumption that you have a team to operationalize the output. For large organizations already on BrightEdge, the Generative Parser is a logical add-on; for everyone else, it’s overkill.
Free and Open-Source GEO Alternatives Worth Knowing
Every competitor roundup skips this section. You don’t always need a paid subscription to start, especially if you’re validating the category before committing budget.
Mangools AI Search Grader free tier
Mangools’ AI Search Grader free tier lets you check how AI engines describe your brand and where you appear for a limited set of prompts at no cost. It won’t replace a continuous monitor, but for a solo marketer or anyone running a first audit, it’s a legitimate way to see your baseline before deciding whether paid monitoring is justified.
GitHub GEO tool lists and AutoGEO-style frameworks
The open-source world has produced curated GitHub lists of GEO tools and AutoGEO-style frameworks — scripts and lightweight pipelines that prompt engines, log citations, and parse the results programmatically. These require technical comfort, but for a developer-leaning team they offer transparent, customizable monitoring with no recurring fee. You control the prompt set, the engines, and the logging, which is more than most paid dashboards expose.
Schema generators and AEO tooling you can use for free
On the production-adjacent side, free schema generators and AEO tools help you mark up content so engines parse it cleanly — FAQ, How-To, Article, and Organization schema all improve a page’s chance of clean retrieval. Combined with solid on-page structure, free structured-data tooling does real work toward making your content citable, no GEO subscription required.
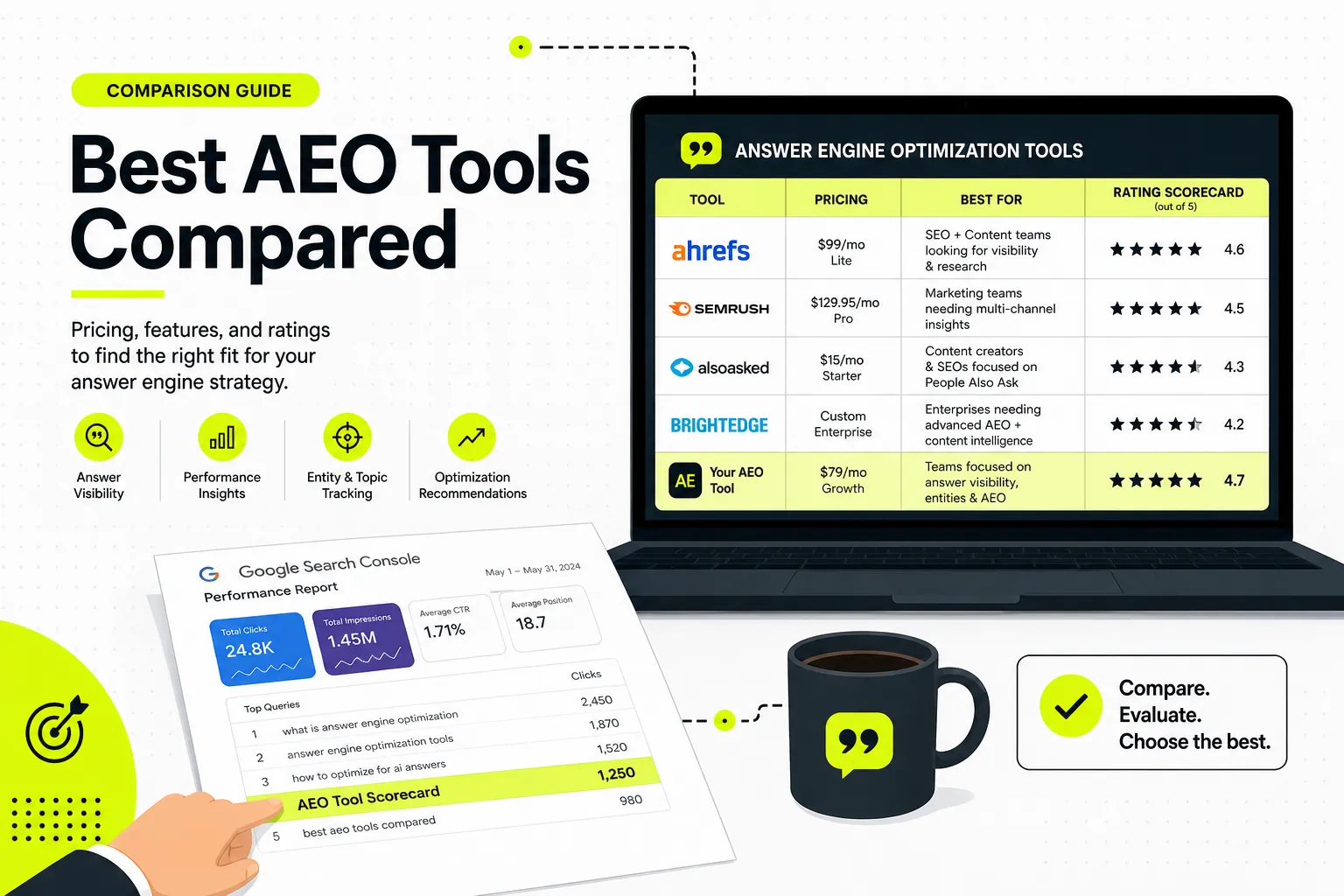
GEO Tools Comparison Table: Features, Pricing, and What Each Actually Does
Monitoring vs. production capability side by side
| Tool | Primary role | Production capability | Engine coverage | Best for |
|---|---|---|---|---|
| Profound | Monitoring | None | Broad | Enterprise |
| AthenaHQ | Monitoring + attribution | None | Broad | Marketing reporting |
| Semrush AIO | Monitoring (within SEO suite) | General SEO tooling | Moderate | Tool consolidators |
| Writesonic | Monitoring + AI writing | Generic AI writing | Moderate | Small teams wanting both |
| Rankscale AI | Monitoring | None | Solid | Mid-market trackers |
| Peec AI | Competitive monitoring | None | Moderate | Competitor benchmarking |
| Goodie AI / GetCito | Monitoring + recommendations | Guidance only | Emerging | Optimization hints |
| Otterly AI | Lightweight monitoring | None | Modest | Solo / small teams |
| BrightEdge | Enterprise monitoring | Within SEO suite | Broad | Existing BrightEdge users |
Pricing tiers and what you really get
Pricing in this category runs from free tiers (Mangools grader, open-source frameworks) through accessible mid-market monitors (Otterly, Rankscale) up to enterprise contracts (Profound, BrightEdge, AthenaHQ at scale). The pattern worth internalizing: you’re almost always paying for monitoring depth and engine coverage. The thing that actually earns citations — content production — is rarely included, or is bolted on as generic AI writing. Budget accordingly: pair an affordable monitor with a real production workflow rather than overpaying for a dashboard you can’t act on.
Vendor claims vs. our GSC-validated findings
The headline finding from cross-checking against Search Console: visibility scores across vendors were directionally similar but not interchangeable, and a few tools reported momentum that had no corresponding signal in GSC query coverage or impressions. Profound, Rankscale, and Peec tracked closest to what we observed manually. The emerging platforms’ optimization recommendations sometimes overstated expected impact. Across the board, tools that integrate or reconcile with first-party search data produced numbers we trusted more — which is exactly why we anchor the whole evaluation to GSC.
Where Dango Fits: The GSC-First Production Layer Behind GEO Visibility
Every tool above is, at its core, a measurement layer. They tell you whether AI engines cite you. None of them solves the problem that measurement reveals: you need more, better, more retrievable content to earn those citations in the first place. That’s the gap Dango fills.
Why monitoring alone doesn’t earn citations
A share-of-voice chart is a symptom report. If Perplexity isn’t citing you for your core topics, the dashboard confirms the loss — it doesn’t fix it. Citations are earned by content that’s retrievable, authoritative, and cleanly structured for the decomposed sub-queries engines fan out into. No amount of monitoring produces that content. Production does. Dango is deliberately a production tool, not another monitor, which is why it complements every platform reviewed here instead of competing with them.
How Dango clusters Search Console data into citable content
Dango is GSC-first by design. It connects to your own Search Console data, clusters real queries and impressions into topic briefs, generates site-aware drafts grounded in what your audience actually searches, and automates internal linking so new pages reinforce existing ones. Because it builds from first-party search demand rather than guesses, the content it helps you produce targets the exact decomposed queries that generative engines retrieve against — the foundational, retrievable, authoritative pages that monitoring tools keep telling you that you’re missing.
Pairing Dango with any GEO monitoring tool in your stack
The ideal stack is simple: keep your monitor of choice — Profound, Rankscale, Otterly, Peec, whatever fits your budget — to see where you stand, and run Dango as the production layer that acts on those findings. Monitor flags a gap in Gemini for a topic cluster; Dango turns your GSC data for that cluster into briefs and drafts; you publish; the monitor confirms movement. That loop — measure, produce, verify — is what actually compounds GEO visibility, and most teams only ever buy the first half of it.
How to Choose a GEO Tool for Your Team Size and Budget
Decision matrix: monitoring, production, or both
Start with one question: do you need to know your AI visibility, change it, or both? If you only need to know, buy a monitor sized to your budget. If you need to change it, you need a production workflow — which most “GEO tools” don’t provide. Almost everyone serious about generative engine optimization needs both, which means a monitor plus a production layer, not a single dashboard pretending to do everything.
| Need | Buy |
|---|---|
| Just measure visibility (tight budget) | Otterly AI or Mangools free tier |
| Measure accurately, mid-market | Rankscale AI or Peec AI |
| Measure + report to stakeholders | AthenaHQ or Profound |
| Actually produce citable content | Dango (GSC-first production) |
| Both, properly | A monitor + Dango |
Picks for solo marketers and small content teams
Keep it lean. Run Mangools’ free grader or Otterly AI for monitoring, lean on free schema generators for structured data, and use Dango to turn your existing Search Console data into a steady stream of briefs and drafts. That combination gives you visibility insight and a real production engine without an enterprise invoice.
Picks for SaaS teams, agencies, and enterprise
Larger teams should pair a deeper monitor — Profound, AthenaHQ, or BrightEdge if you’re already on it — with a production layer that scales. Agencies juggling multiple clients benefit most from a GSC-first workflow like Dango that clusters each client’s own search data into publishable content, because that’s the work that doesn’t scale by hiring alone. The monitor proves the result to the client; the production layer creates it.
Frequently Asked Questions
Are paid generative engine optimization tools worth it, or can free alternatives do the job?
For a first audit or a solo marketer, free options — Mangools’ AI Search Grader, open-source frameworks, free schema generators — genuinely do the job of establishing a baseline. Paid monitors earn their cost once you need continuous tracking across many prompts and engines or stakeholder reporting. The bigger truth: the money is best spent on production, since that’s what changes the numbers a monitor reports.
How accurate is the AI visibility data these GEO tools report?
Directionally useful, not gospel. In our testing the better tools (Profound, Rankscale, Peec) tracked closely to manual prompt checks, while a few reported momentum with no corresponding signal in first-party Search Console data. Always validate a tool’s visibility scores against your own manual checks and GSC before trusting them for decisions.
Can a GEO tool actually improve my citations, or only measure them?
The vast majority only measure. A handful (Writesonic, Goodie AI, GetCito) add content or recommendation features, but most are pure monitors. Improving citations requires producing retrievable, authoritative content — which is a production task. That’s why pairing a monitor with a production layer like Dango is the combination that actually moves visibility.
How often should I check my brand’s visibility across AI engines?
Weekly is plenty for most teams; engine answers don’t change minute to minute, and obsessing over daily fluctuations wastes attention. Set a weekly review for share of voice on your core prompts, and run a deeper monthly audit alongside your GSC data to confirm that real movement, not noise, is happening.
Do I still need traditional SEO if I use a GEO tool?
Yes — more than ever. Generative engines retrieve from the open web and from Google’s index, so crawlability, relevance, authority, and useful content are the prerequisites for being citable at all. GEO visibility is a downstream result of strong SEO, not a replacement for it. A GEO tool tells you how that foundation is performing in AI answers; it doesn’t excuse skipping the foundation.
Which GEO tools integrate with Google Search Console data?
Few monitoring tools use GSC as a core input — most query AI engines directly and treat search data as separate. Semrush and the larger SEO suites surface ranking data alongside AI visibility. On the production side, Dango is built GSC-first: it clusters your Search Console queries and impressions into the briefs and drafts that earn citations, which is the integration that matters most for actually improving visibility.
How long does it take to see results after using a GEO optimization tool?
Monitoring shows your current state immediately. Improvement takes longer: publishing new content, getting it crawled and indexed, and earning retrieval in AI answers typically unfolds over weeks to a few months, similar to SEO timelines. Engines that lean on Google’s index (Gemini) tend to reflect changes once your pages rank; Perplexity can pick up well-structured new content faster.
Can one tool track visibility across ChatGPT, Perplexity, Gemini, and Claude at once?
Most major monitors — Profound, AthenaHQ, Rankscale, Peec, Semrush — claim multi-engine coverage and do track the big four to varying depth. No single tool tracks every engine, including DeepSeek, with equal fidelity, so coverage and accuracy differ by platform. Verify which engines a tool actually queries during a trial rather than trusting a “full coverage” headline.